Importing data
Data tidying and importing
Reading delimited files

read_csv()- comma delimited filesread_csv2()- semicolon separated files (common in countries where , is used as the decimal place)read_tsv()- tab delimited filesread_delim()- reads in files with any delimiterread_fwf()- fixed width files- …
Reading Excel spreadsheets

Option 1 - Quote column names
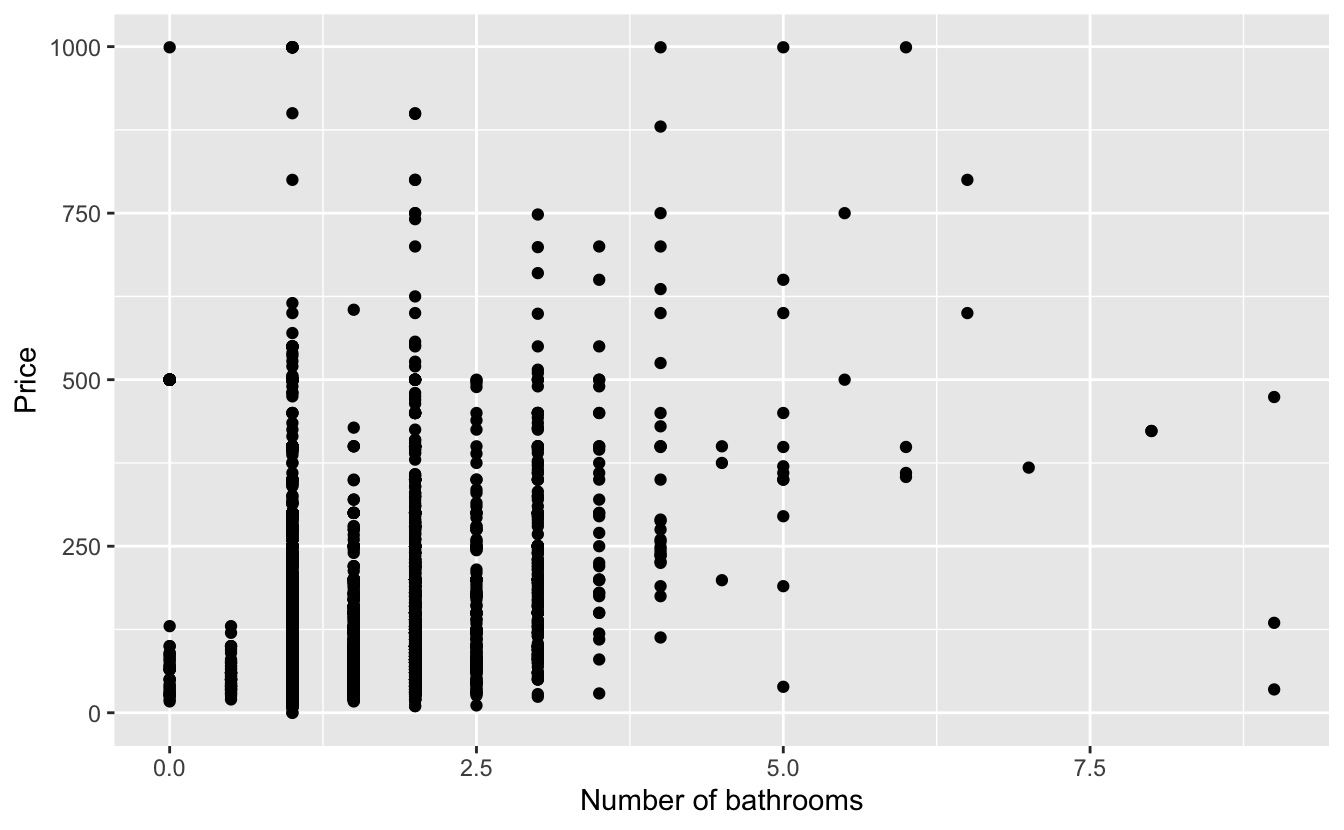
Variable types
Which type is x? Why?
Option 1. Explicit NAs
# A tibble: 9 × 3
x y z
<dbl> <chr> <chr>
1 1 a hi
2 NA b hello
3 3 <NA> <NA>
4 4 d ola
5 5 e hola
6 NA f whatup
7 7 g wassup
8 8 h sup
9 9 i <NA> 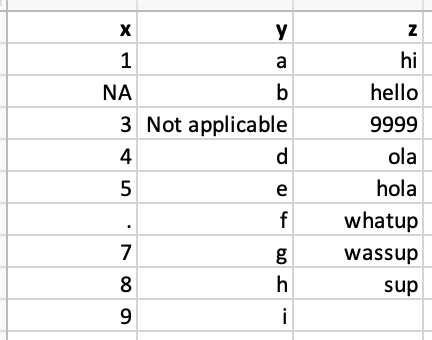
Option 2. Specify column types
Warning: One or more parsing issues, call `problems()` on your data
frame for details, e.g.:
dat <- vroom(...)
problems(dat)# A tibble: 9 × 3
x y z
<dbl> <chr> <chr>
1 1 a hi
2 NA b hello
3 3 Not applicable 9999
4 4 d ola
5 5 e hola
6 NA f whatup
7 7 g wassup
8 8 h sup
9 9 i <NA>