Bechdel + data visualization
Data visualization and transformation
Data Science with R
Please reference the Meet the toolkit: Programming exercises for information and instructions on how to interact with the programming exercise below.
Getting started
Please run the following code by clicking the green arrow just above the code chunk. When reading in the data, nothing will appear after you click the button. However, clicking the arrow ensures that your data can be used for the following programming exercise.
Note: Reading in a tibble also gives you information about the data, such as the column names (e.g., tite), and the variable type (e.g., chr). This is often suppressed after the initial read in by adding show_col_types = FALSE within the read_csv() function after the path to the data, separated by a comma.
In this mini analysis we work with the data used in the FiveThirtyEight story titled “The Dollar-And-Cents Case Against Hollywood’s Exclusion of Women”.
This analysis is about the Bechdel test, a measure of the representation of women in fiction.
Packages
We’ll use: tidyverse for the majority of the analysis and scales for pretty plot labels later on. These are ready for you to use in this programming exercise!
This a modified version of the bechdel dataset. It’s been modified to include some new variables derived from existing variables as well as to limit the scope of the data to movies released between 1990 and 2013. A link to the original dataset can be found here
Get to know the data
We can use the glimpse() function to get an overview (or “glimpse”) of the data. Write the following code below to accomplish this task.
With your output, confirm that:
There are 1615 rows
There are 7 variables (columns) in the dataset
If you receive the error Error: object ‘bechdel’ not found, go back and read in your data above with read_csv().
glimpse(bechdel)Rows: 1,615
Columns: 7
$ title <chr> "21 & Over", "Dredd 3D", "12 Years a Slave", "2 Guns", "42…
$ year <dbl> 2013, 2012, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013…
$ gross_2013 <dbl> 67878146, 55078343, 211714070, 208105475, 190040426, 18416…
$ budget_2013 <dbl> 13000000, 45658735, 20000000, 61000000, 40000000, 22500000…
$ roi <dbl> 5.221396, 1.206305, 10.585703, 3.411565, 4.751011, 0.81851…
$ binary <chr> "FAIL", "PASS", "FAIL", "FAIL", "FAIL", "FAIL", "FAIL", "P…
$ clean_test <chr> "notalk", "ok", "notalk", "notalk", "men", "men", "notalk"…We can use slice() to look at rows of our data. Run the following code. Change the 5 to another number to print that many rows!
What does each observation (row) in the data set represent?
Each observation represents a movie.
Variables of interest
The variables we’ll focus on are the following:
-
budget_2013: Budget in 2013 inflation adjusted dollars. -
gross_2013: Gross (US and international combined) in 2013 inflation adjusted dollars. -
roi: Return on investment, calculated as the ratio of the gross to budget. -
clean_test: Bechdel test result:-
ok= passes test dubious-
men= women only talk about men -
notalk= women don’t talk to each other -
nowomen= fewer than two women
-
-
binary: Bechdel Test PASS vs FAIL binary
There are a few other variables in the dataset, but we won’t be using them in this analysis.
Visualizing data with ggplot2
ggplot2 is the package and ggplot() is the function in this package that is used to create a plot. Interact with the code below by either running the code given, or adding code to achieve the expected solution when asked within the code chunk!
-
ggplot()creates the initial base coordinate system, and we will add layers to that base. We first specify the data set we will use withdata = bechdel, and run the following to create our base.
- The
mappingargument is paired with an aesthetic (aes()), which tells us how the variables in our data set should be mapped to the visual properties of the graph.
- As we previously mentioned, we often omit the names of the first two arguments in R functions. So you’ll often see this written as:
Note that the result is exactly the same.
The geom_*() function specifies the type of plot we want to use to represent the data. In the code below, we want to use geom_point(), which creates a plot where each observation is represented by a point.
ggplot(
bechdel,
aes(x = budget_2013, y = gross_2013)
) +
geom_point()Warning: Removed 15 rows containing missing values or values outside the scale range
(`geom_point()`).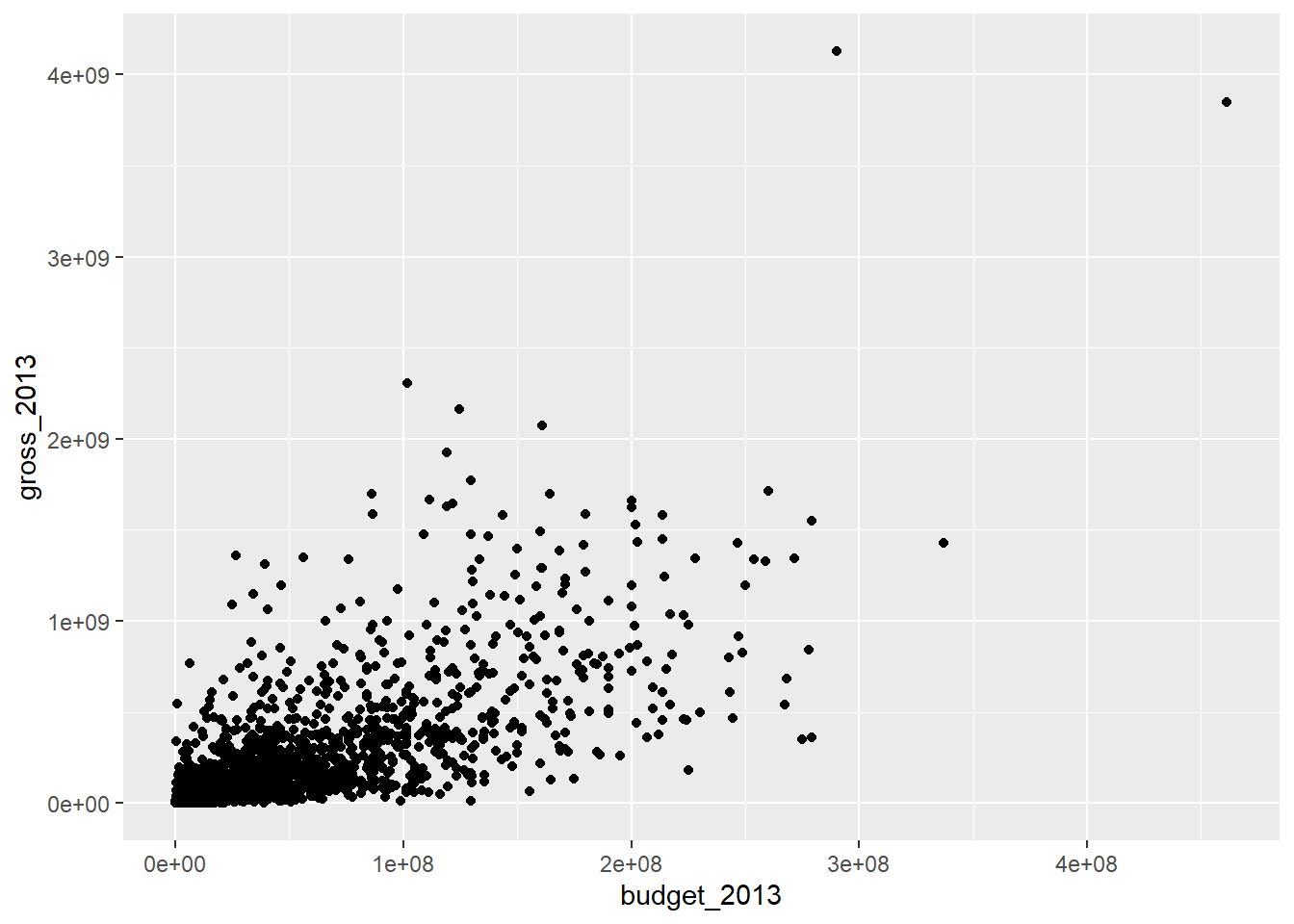
Note that this results in a warning as well.
This warning represents the number of observations that were removed because there were missing data!
Gross revenue vs. budget
Step 1
The following code changes the color of all points to coral. Explore different colors by changing “coral” to different colors!
See http://www.stat.columbia.edu/~tzheng/files/Rcolor.pdf for many color options you can use by name in R or use the hex code for a color of your choice.
Step 2
Add labels for the title and x and y axes using labs(). Do this by modifying the existing code below.
ggplot(
bechdel,
aes(x = budget_2013, y = gross_2013)
) +
geom_point(color = "deepskyblue3") +
labs(
x = "Budget (in 2013 $)",
y = "Gross revenue (in 2013 $)",
title = "Gross revenue vs. budget"
)Warning: Removed 15 rows containing missing values or values outside the scale range
(`geom_point()`).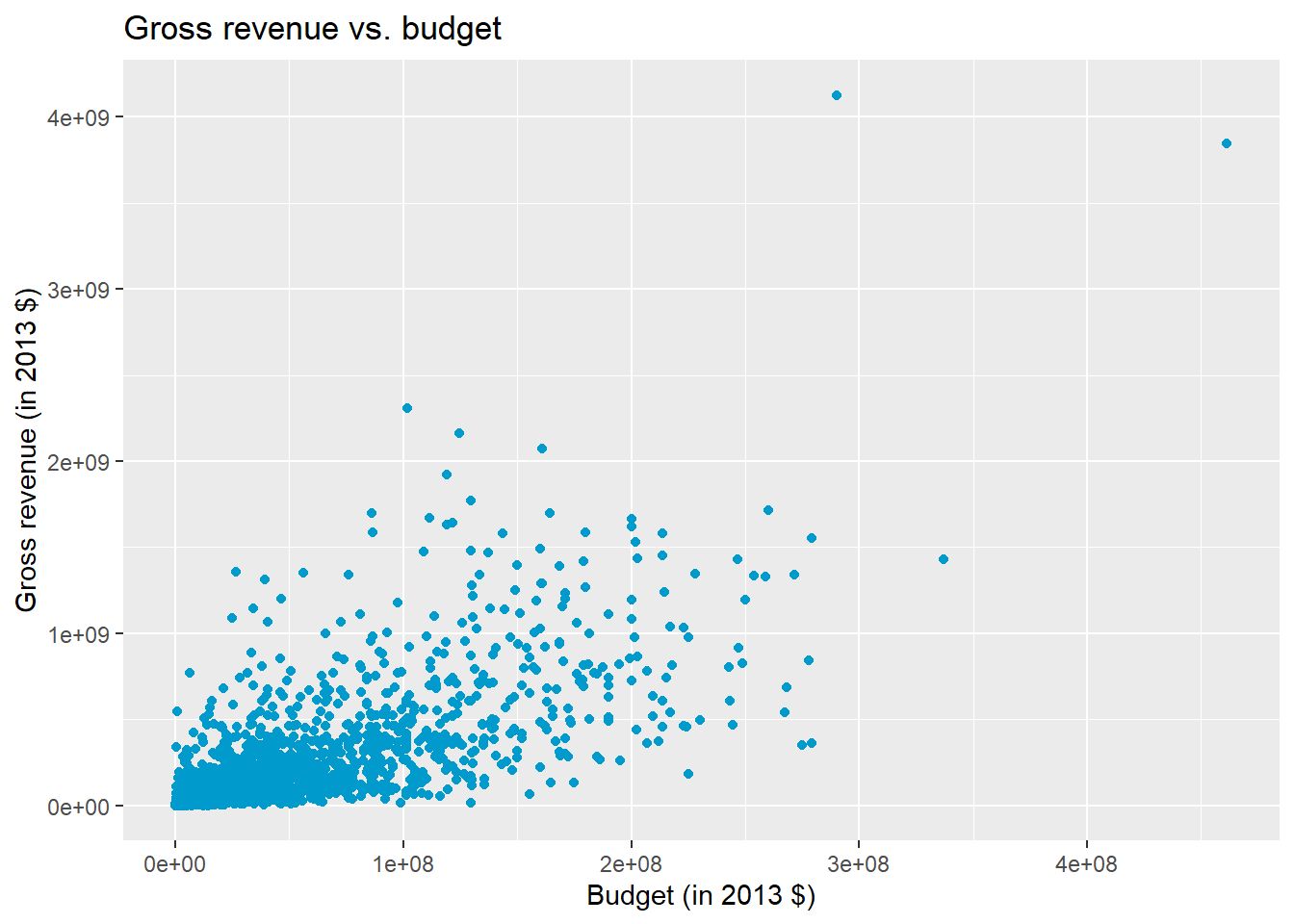
Step 3
An aesthetic is a visual property of one of the objects in your plot. Commonly used aesthetic options are:
- color
- fill
- shape
- size
- alpha (transparency)
Modify the plot below so the color of the points is based on the variable binary, and make the size of your points based on roi.
ggplot(
bechdel,
aes(
x = budget_2013, y = gross_2013,
color = binary, size = roi
)
) +
geom_point() +
labs(
x = "Budget (in 2013 $)",
y = "Gross revenue (in 2013 $)",
title = "Gross revenue vs. budget, by Bechdel test result"
)Warning: Removed 15 rows containing missing values or values outside the scale range
(`geom_point()`).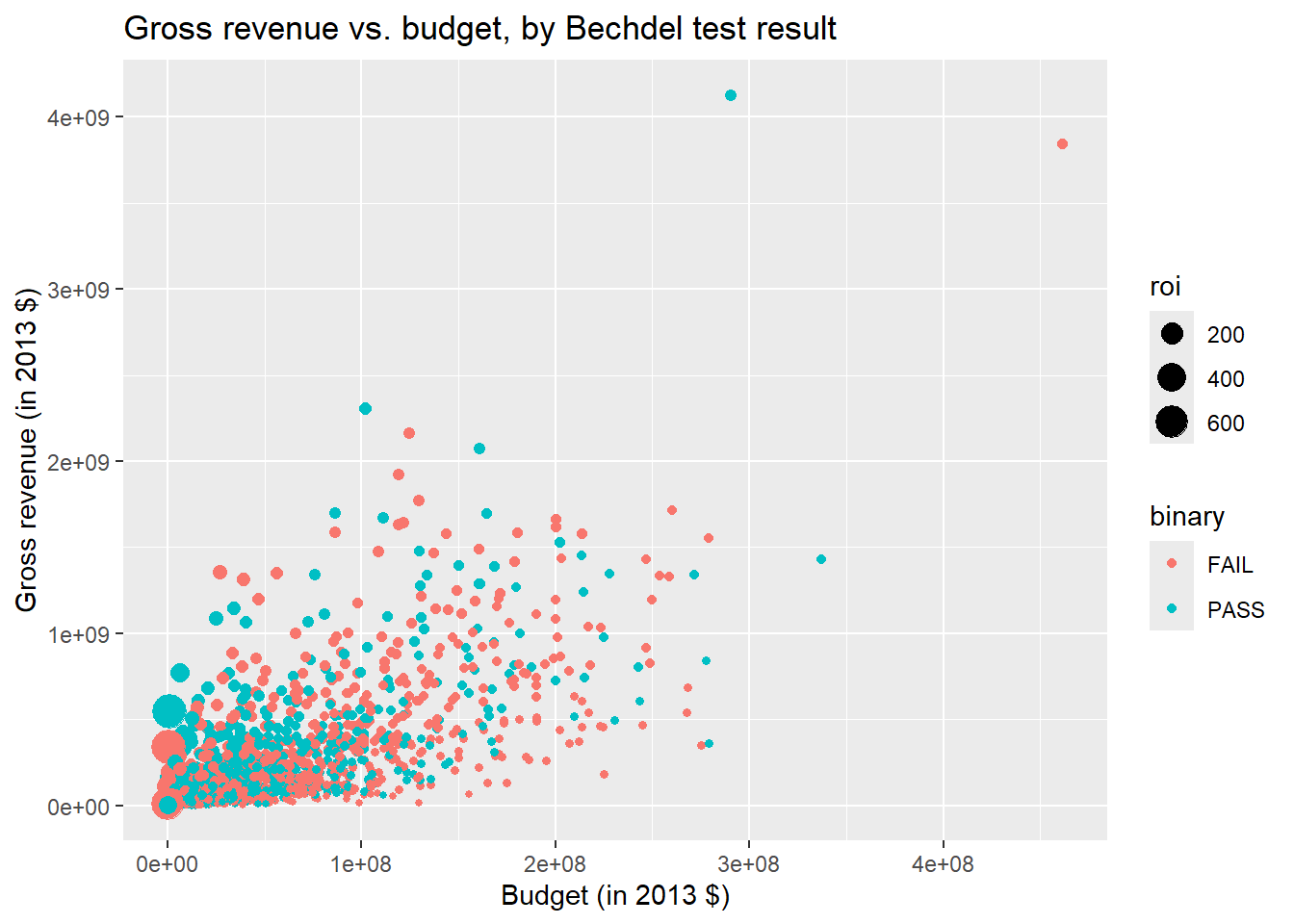
Step 4
alpha is used within geom_point() to change the transparency of the dots. alpha ranges between 0 and 1, with lower values being more transparent dots. Below, make the dots more transparent.
Step 5
Expand on your plot from the previous step by using facet_wrap() to display the association between budget and gross for different values of clean_test.
ggplot(
bechdel,
aes(
x = budget_2013, y = gross_2013,
color = binary, size = roi
)
) +
geom_point(alpha = 0.5) +
facet_wrap(~clean_test) +
labs(
x = "Budget (in 2013 $)",
y = "Gross revenue (in 2013 $)",
title = "Gross revenue vs. budget, by Bechdel test result"
)Warning: Removed 15 rows containing missing values or values outside the scale range
(`geom_point()`).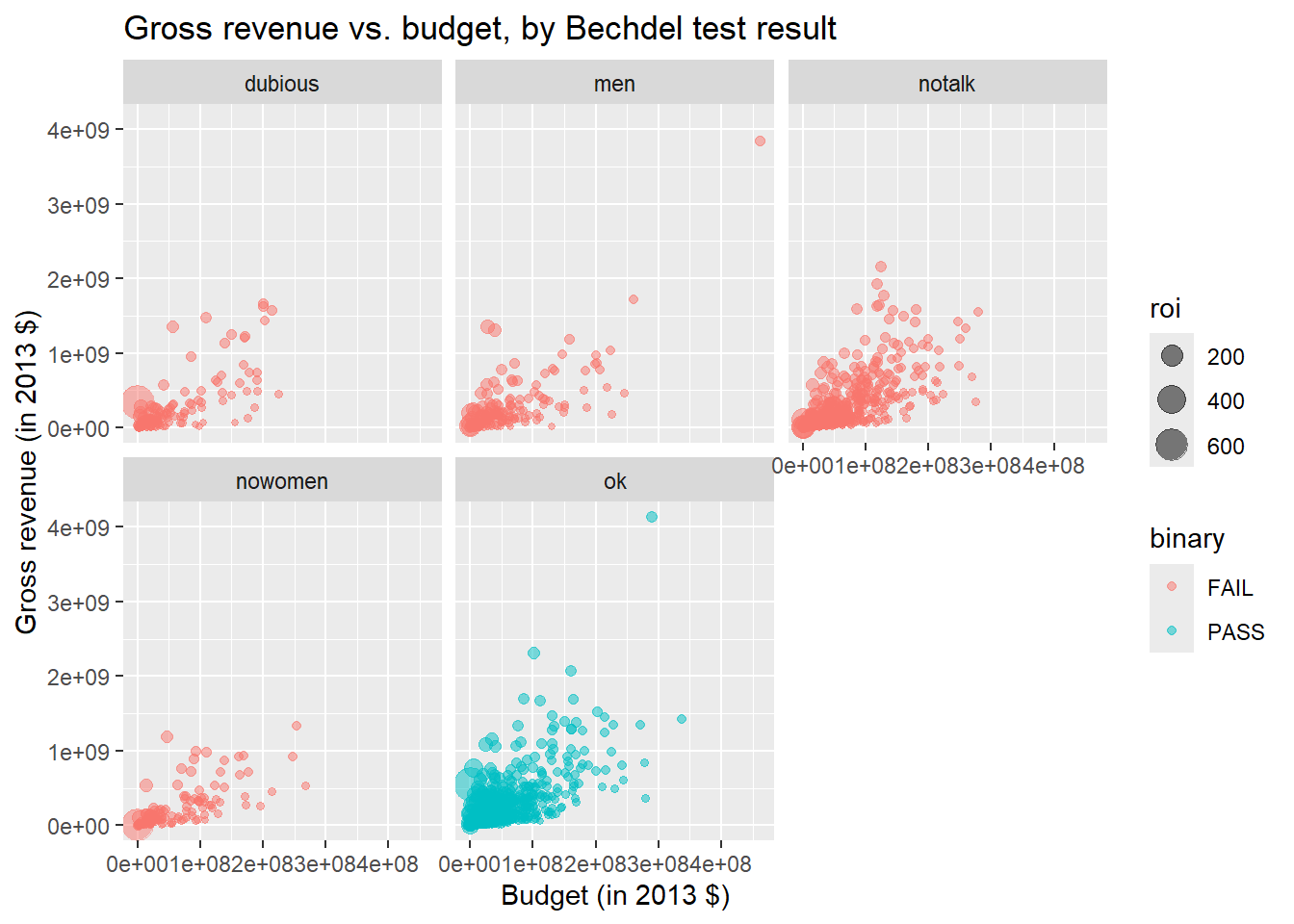
Step 6
Below is a demonstration on how to improve your plot from the previous step by making the x and y scales more legible.
This is done through the use of the scales package, specifically the scale_x_continuous() and scale_y_continuous() functions.
Step 7
Expand on your plot from the previous step by using facet_grid() to display the association between budget and gross for different combinations of clean_test and binary.
Is this type of facet useful? Why or why not?
ggplot(
bechdel,
aes(
x = budget_2013, y = gross_2013,
color = binary, size = roi
)
) +
geom_point(alpha = 0.5) +
facet_grid(clean_test ~ binary) +
scale_x_continuous(labels = label_dollar(scale = 1 / 1000000)) +
scale_y_continuous(labels = label_dollar(scale = 1 / 1000000)) +
labs(
x = "Budget (in 2013 $)",
y = "Gross revenue (in 2013 $)",
title = "Gross revenue vs. budget, by Bechdel test result"
)Warning: Removed 15 rows containing missing values or values outside the scale range
(`geom_point()`).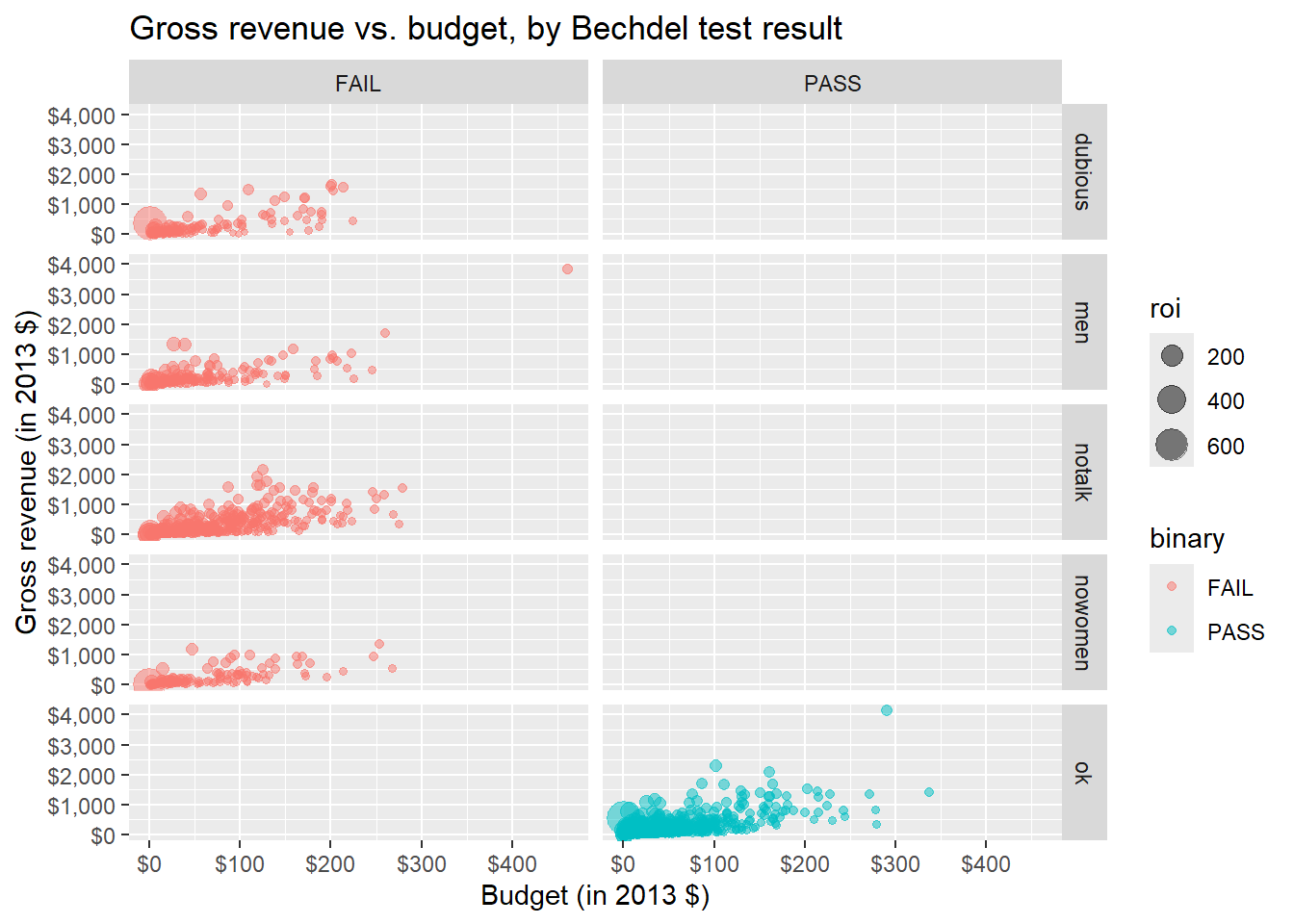
This was not a useful update as one of the levels of clean_test maps directly to one of the levels of binary.