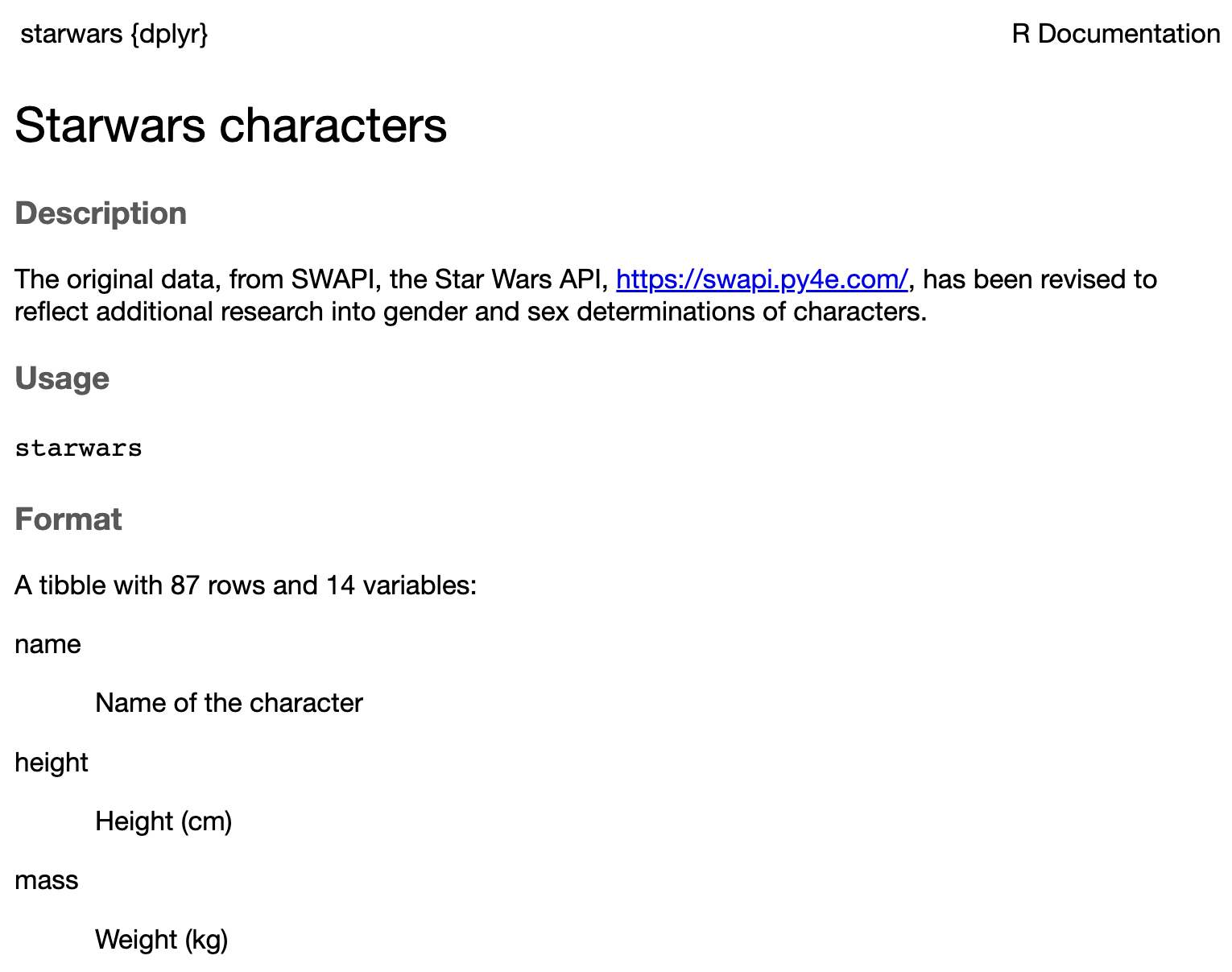
# A tibble: 87 × 14
name height mass hair_color skin_color eye_color
<chr> <int> <dbl> <chr> <chr> <chr>
1 Luke Skywal… 172 77 blond fair blue
2 C-3PO 167 75 <NA> gold yellow
3 R2-D2 96 32 <NA> white, bl… red
4 Darth Vader 202 136 none white yellow
5 Leia Organa 150 49 brown light brown
6 Owen Lars 178 120 brown, gr… light blue
7 Beru Whites… 165 75 brown light blue
8 R5-D4 97 32 <NA> white, red red
9 Biggs Darkl… 183 84 black light brown
10 Obi-Wan Ken… 182 77 auburn, w… fair blue-gray
# ℹ 77 more rows
# ℹ 8 more variables: birth_year <dbl>, sex <chr>,
# gender <chr>, homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>Visualizing data
Data visualization and transformation
Luke Skywalker

Get to know the data
How many rows and columns does this dataset have? What does each row represent? What does each column represent?
Mass vs. height
How would you describe the relationship between mass and height of Star Wars characters? What other variables would help us understand data points that don’t follow the overall trend? Who is the not so tall but really chubby character?
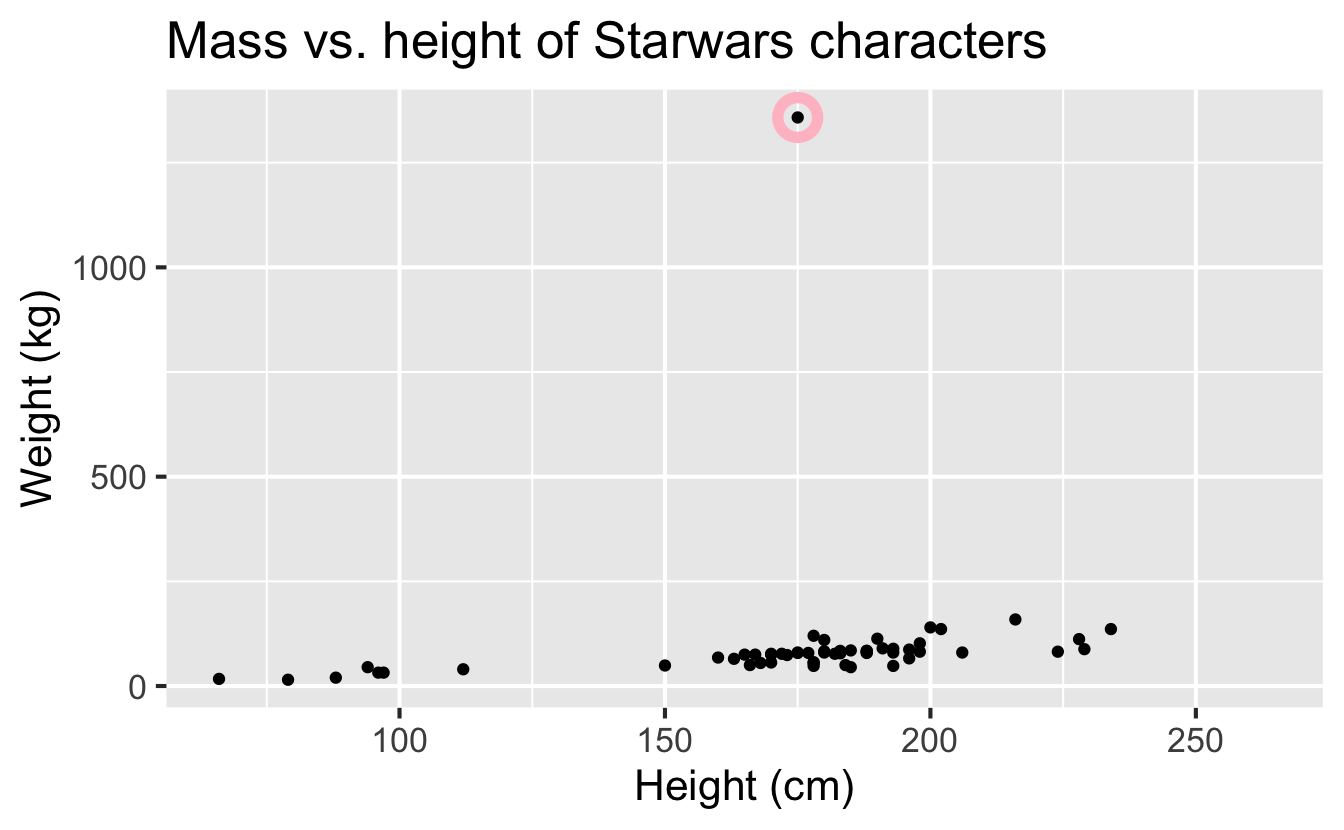
Jabba!

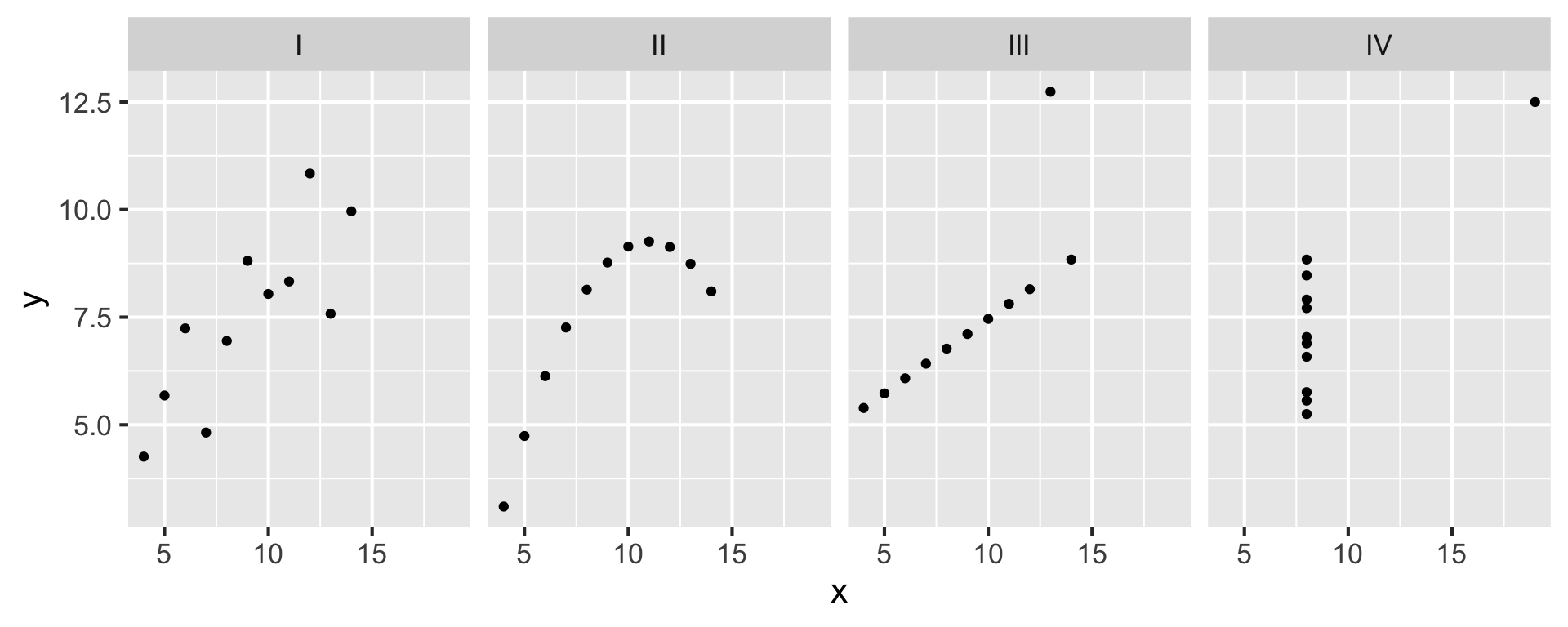
Visualizing Anscombe’s quartet
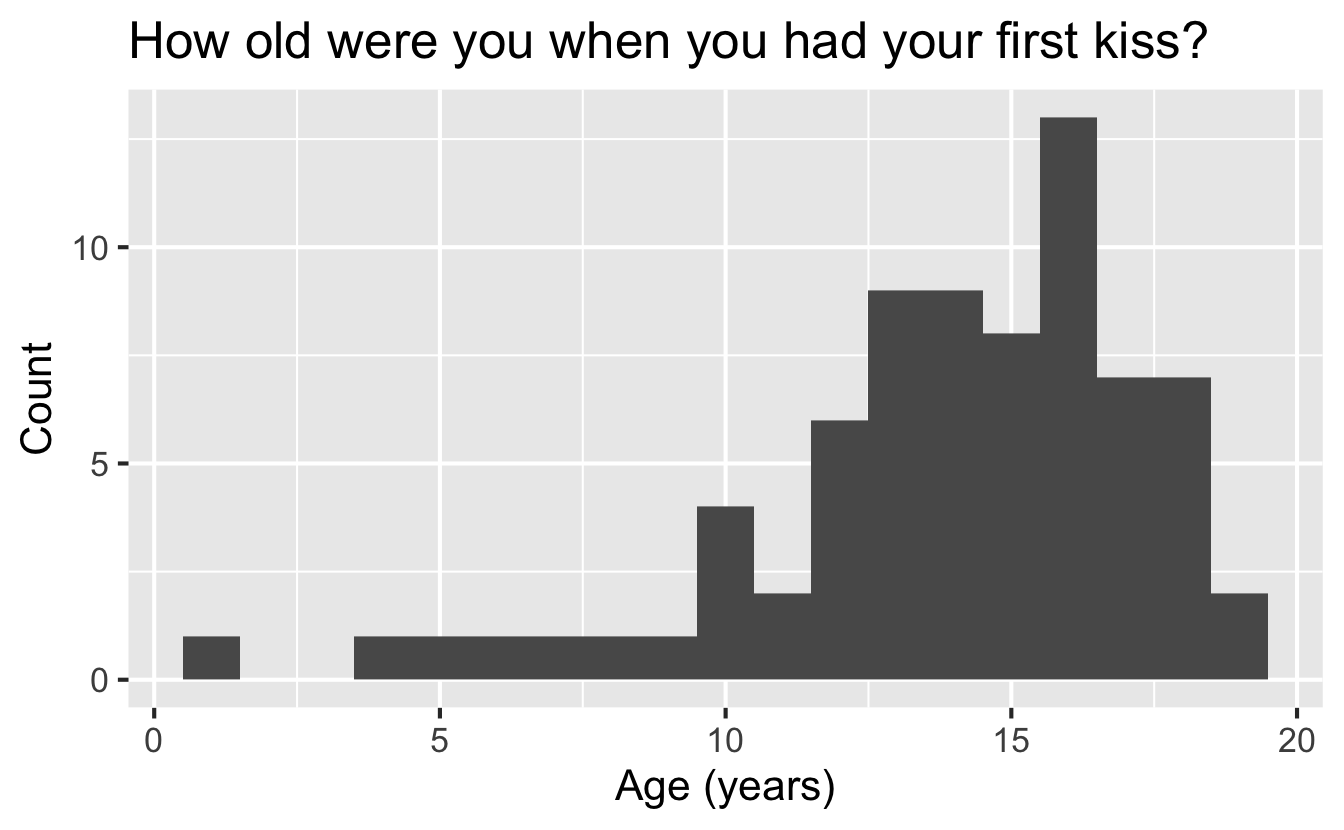
Age at first kiss
A group of college students were asked “How old were you when you had your first kiss?” on a survey. First, think about how you might expect the distribution of their responses to look.
Then, examine the plot below. Do you see anything out of the ordinary?
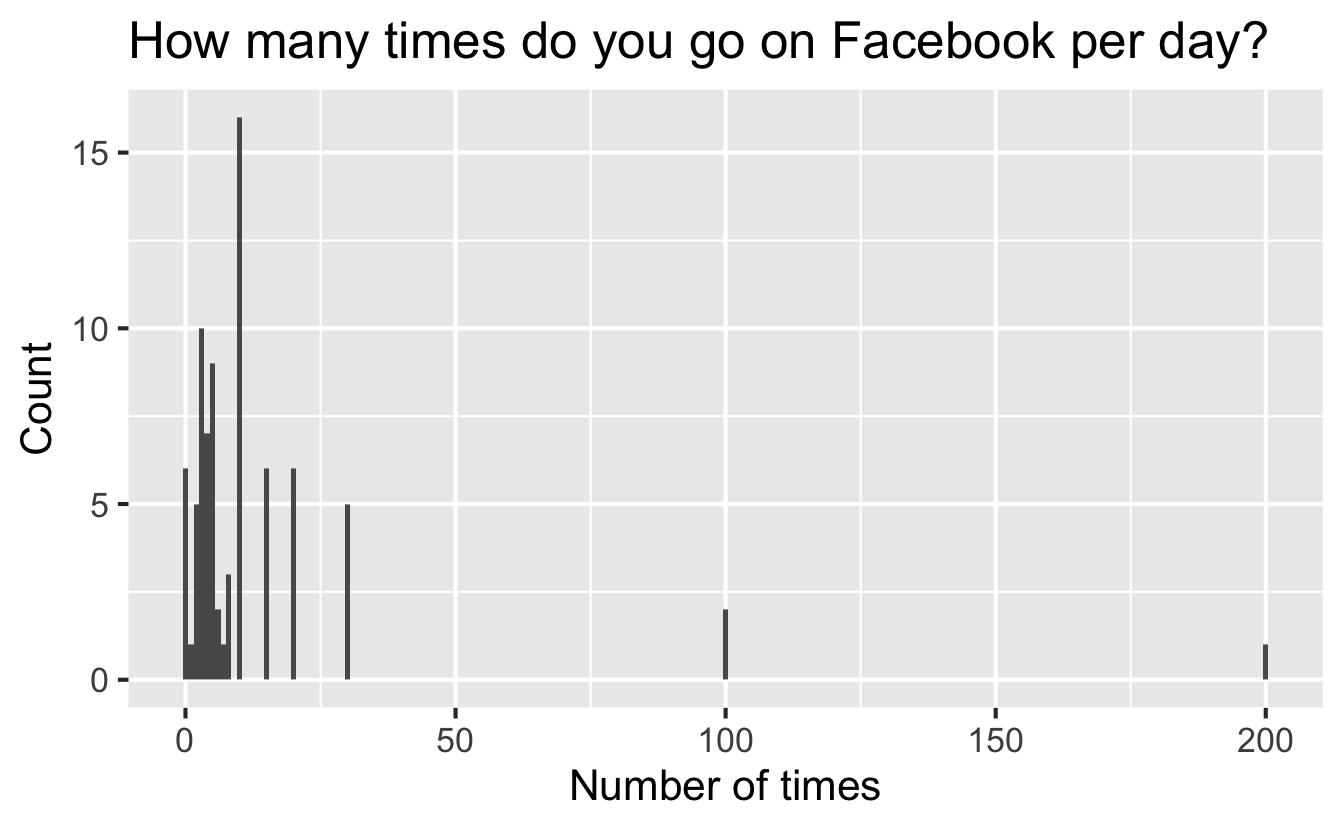
Facebook visits
Same group of college students were also asked “How many times do you go on Facebook per day?” First, think about how you might expect the distribution of their responses to look.
Then, examine the plot below. How are people reporting lower vs. higher values of FB visits?