Predicting NBA salaries with multiple linear regression
Modeling Inference
Data Science with R
Getting Started
Programming exercises are designed to provide an opportunity for you to put what you learn in the videos and readings. These exercises feature interactive code cells which allow you to write, edit, and run R code without leaving your browser.
When the ▶️ Run Code button turns to a solid color (with no flashing bubble indicating that the document is still loading), you can interact with the code cells!
Packages
We’ll use the tidyverse and tidymodels for this programming exercise. These are already installed for you to use!
Motivation
The National Basketball Association (NBA) is a professional sports league that consists of 30 teams across the United States and Canada. In the early 2000s, NBA teams started to use advanced analytics to gain a competitive edge over their opponents. Teams employ the use of analytics to make data driven decisions on game strategy and business operations. In this programming exercise, we are going to work with NBA data to try and better understand the salary NBA players make.
Data
This dataset consists of player per-game statistics for the NBA’s 2022-23 season with player salary data. We are going to use just a subset of these variables in this programming exercise. The variables we will use can be seen below. The data key for the entire dataset can be revealed below.
| Variable | Description |
|---|---|
| Salary | Yearly salary a NBA players make in USD |
| Position | Position on the court the NBA player plays: PG, SG, SF, PF, and C |
| Age | Age of the player, rounded to the nearest year |
CautionData dictionary
Need to expand
| Variable | Description |
|---|---|
| Salary | Yearly salary a NBA players make in USD |
| Position | Position on the court the NBA player plays: PG, SG, SF, PF, and C |
| Age | Age of the player, rounded to the nearest year |
| Team | Team of the NBA player |
| GP | Total number of games played |
| GS | Total number of games the player started |
| MP | Average number of minutes played |
| FG | The total number of shots made (2P + 3P) |
| FGA | The total number of shots taken (2PA + 3PA) |
| FG% | The percentage of all shots made (FG / FGA) |
| 3P | The total number of 3-point shots made |
| 3PA | The total number of 3-point shots taken |
| 3P% | The percentage of 3-point shots made (3P / 3PA) |
| 2P | Total number of 2-point shots made |
| 2PA | Total number of 2-point shots attempted |
| eFG% | Effective Field Goal Percentage ( (FG + 0.5*3P) / FGA) ) |
| FT | Total number of free throws made |
| FTA | The total free throws attempted |
| FT% | The percent of FTs made (FT / FTA) |
| ORB | Average offensive rebounds per game |
| DRB | Average defensive rebounds per game |
| TRB | Total rebounds (ORB + DRB) per game |
| AST | Average assists per game |
| STL | Average steals per game played |
| BLK | Average blocks per game played |
| TOV | Average turnovers per game |
| PF | Average fouls accrued per game played |
| PTS | Average points scored per game played |
Now, let’s explore these data!
Exploratory data analysis
Before we fit a linear regression model, we are going to explore the data. Let’ start with exploring our response variable of interest, cholesterol (Salary). Specifically, we are interested in the relationship between Salary, Age, and Position. Below, calculate the mean and standard deviation for your quantitative variables. In the same code, produce the count of each position.
TipSolution
nba |>
group_by(Position) |>
summarize(
mean_salary = mean(Salary, na.rm = TRUE),
sd_salary = sd(Salary, na.rm = TRUE),
mean_age = mean(Age, na.rm = TRUE),
sd_age = sd(Age, na.rm = TRUE),
position_n = n()
)# A tibble: 5 × 6
Position mean_salary sd_salary mean_age sd_age position_n
<chr> <dbl> <dbl> <dbl> <dbl> <int>
1 C 7282722. 8983558. 26.3 4.48 91
2 PF 8885045. 10897789. 26.6 4.78 86
3 PG 11579573. 13889342. 26.2 4.35 77
4 SF 8132253. 11055604. 25.6 3.64 91
5 SG 6681301. 8308597. 24.7 3.85 115Modeling
Visualizing the model
We are now going to plot our response variable Salary vs Age using a scatterplot. We are also going to color the points based on Position. The plot can be seen below.
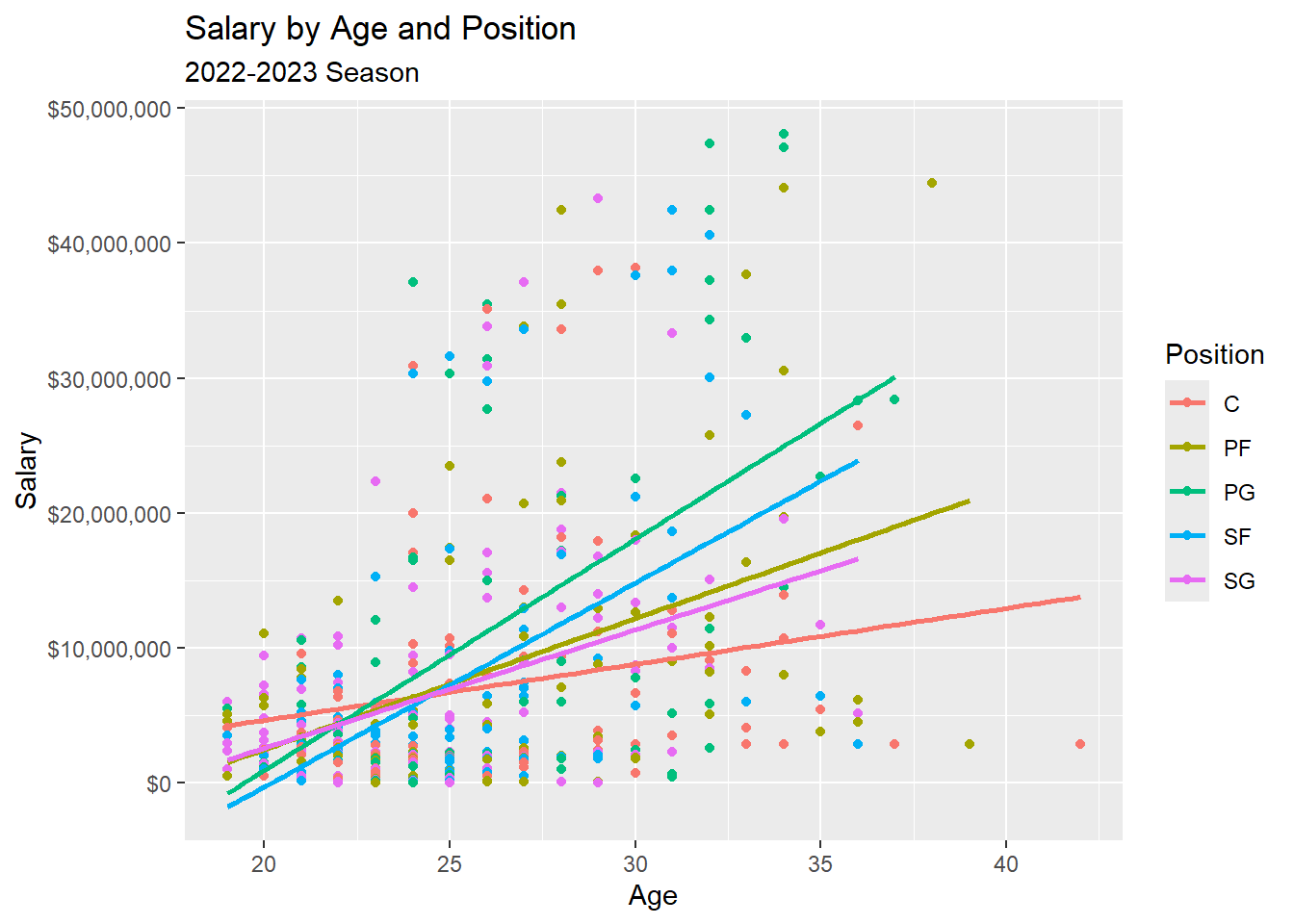
From the videos, we learned about two different times of multiple linear regression models that we could fit:
Main effects models: The relationship between x and y does not change based on z
Interaction effects models: The relationship between x and y does change by z
(Thought exercise) Based on these definitions, do you think it would be appropriate to fit an main effects or an interaction effects model?
TipSolution
It is justifiable to fit an interaction effects model instead of a main effects model. Based on the scatterplot, we can see that the relationship between Salary and Age changes depending on the position the player plays.
Multiple linear regression
So we can explore both concepts, regardless of your conclusion in the though exercise, we are first going to fit a main effects model. We are going to this to:
Show that R will still fit the model, despite it not being the most appropriate
Practice fitting main effects models
Practice interpreting main effects model output
Main effects model
Fit the main effects model below. Name this model m1, and wrap this object in the tidy() function. Next, interpret the estimate for PositionPF in the context of the problem.
TipSolution
sal_main_fit <- linear_reg() |>
fit(Salary ~ Age + Position, data = nba)
tidy(sal_main_fit)# A tibble: 6 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -20019456. 2996402. -6.68 6.96e-11
2 Age 1038670. 107316. 9.68 2.88e-20
3 PositionPF 1307286. 1449993. 0.902 3.68e- 1
4 PositionPG 4391276. 1492626. 2.94 3.43e- 3
5 PositionSF 1602852. 1431168. 1.12 2.63e- 1
6 PositionSG 1095288. 1363752. 0.803 4.22e- 1As an NBA player ages one year, we estimate a mean salary increase of 1,307,286 usd if they play PF.
(Thought exercise) What position do you not see a term for? Where is it?
TipSolution
We don’t see a specific term for C. That is because it’s our (Intercept) term! We can interpret the intercept as: For an age of, we estimate the mean salary of an NBA C to be -2,0019,456 usd. Each other position estimate is the estimated difference in Salary relative to the C, after controlling for Age!
We can change the intercept. See the following code that changes the intercept to PG, and notice how the estimates change based on what our intercept term is! Note: Age does not change, because the relationship between Salary and Age does not depend on Position.
nba_diff <- nba |>
mutate(Position = fct_relevel(Position, "PG"))
sal_main_2_fit <- linear_reg() |>
fit(Salary ~ Age + Position, data = nba_diff)
tidy(sal_main_2_fit)# A tibble: 6 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -15628180. 3018134. -5.18 3.38e- 7
2 Age 1038670. 107316. 9.68 2.88e-20
3 PositionC -4391276. 1492626. -2.94 3.43e- 3
4 PositionPF -3083990. 1512886. -2.04 4.21e- 2
5 PositionSF -2788424. 1494146. -1.87 6.27e- 2
6 PositionSG -3295988. 1429037. -2.31 2.15e- 2Interaction effects model
Now, it’s time to fit the interaction effects model between Salary, Age, and Position. Please do so below, and interpret the Age:PositionPF interaction term.
TipSolution
sal_int_fit <- linear_reg() |>
fit(Salary ~ Age * Position, data = nba)
tidy(sal_int_fit)# A tibble: 10 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -3607189. 5950994. -0.606 0.545
2 Age 414290. 223212. 1.86 0.0641
3 PositionPF -13289313. 8318463. -1.60 0.111
4 PositionPG -29720679. 8918015. -3.33 0.000931
5 PositionSF -26887800. 9258556. -2.90 0.00386
6 PositionSG -11312489. 8280299. -1.37 0.173
7 Age:PositionPF 556044. 310153. 1.79 0.0737
8 Age:PositionPG 1300074. 335283. 3.88 0.000121
9 Age:PositionSF 1096922. 353991. 3.10 0.00207
10 Age:PositionSG 461940. 321063. 1.44 0.151 For a Power Forward, a one-year increase in age, we estimate on average an increase in salary of approximately 970,334 usd.
Why 970,334? The term Age:PositionPF has a coefficient of 556,044. This is the estimated difference in the slope coefficient vs the Center position. Thus, the slope coefficient specifically for the PF position is estimated to be 414,290 larger than the baseline.
Note: This is the mathematical representation to the plot created above!
If we do change the baseline term, the Age coefficient will also change, because the interaction term allows for the relationship between Age and Salary to change based on Position. Let’s see this below.
sal_int_2_fit <- linear_reg() |>
fit(Salary ~ Age * Position, data = nba_diff)
tidy(sal_int_2_fit)# A tibble: 10 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -33327869. 6642038. -5.02 7.54e- 7
2 Age 1714364. 250181. 6.85 2.40e-11
3 PositionC 29720679. 8918015. 3.33 9.31e- 4
4 PositionPF 16431366. 8826050. 1.86 6.33e- 2
5 PositionSF 2832880. 9717161. 0.292 7.71e- 1
6 PositionSG 18408190. 8790091. 2.09 3.68e- 2
7 Age:PositionC -1300074. 335283. -3.88 1.21e- 4
8 Age:PositionPF -744030. 330094. -2.25 2.47e- 2
9 Age:PositionSF -203152. 371586. -0.547 5.85e- 1
10 Age:PositionSG -838134. 340365. -2.46 1.42e- 2Summary
Multiple linear regression allows for a single quantitative variable to be modeled by > 1 predictor variable.
An main effects model has the restriction of keeping the relationship between x and y consistent , regardless of the values of the other variables in the model.
An interaction effects model relaxes this restriction, and allows the relationship between x and y to change based on values of z.
Regression output has a baseline group when one predictor variable is categorical. This can be found in the
Interceptterm, with the other categorical level coefficients representing the deviation from the baseline.
Your turn: Challenge
Use this space to fit more complicated models, and explore different relationships that model our response variable Salary! As a reminder, the complete data dictionary can be found above.